The Truthfulness Spectrum Hypothesis
Abstract
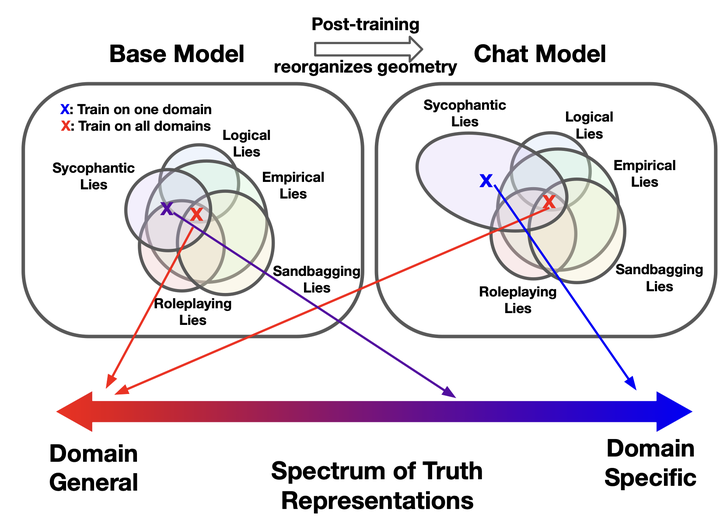
Large language models (LLMs) have been reported to linearly encode truthfulness, yet recent work questions this finding’s generality. We reconcile these views with the truthfulness spectrum hypothesis: the representational space contains directions ranging from broadly domain-general to narrowly domain-specific. To test this hypothesis, we systematically evaluate probe generalization across five truth types (definitional, empirical, logical, fictional, and ethical), sycophantic and expectation-inverted lying, and existing honesty benchmarks. Linear probes generalize well across most domains but fail on sycophantic and expectation-inverted lying. Yet training on all domains jointly recovers strong performance, confirming that domain-general directions exist despite poor pairwise transfer. The geometry of probe directions explains these patterns: Mahalanobis cosine similarity between probes near-perfectly predicts cross-domain generalization (R^2=0.98).