 Qantifying the ability to recover linearly-erased concept information.
Qantifying the ability to recover linearly-erased concept information.Abstract
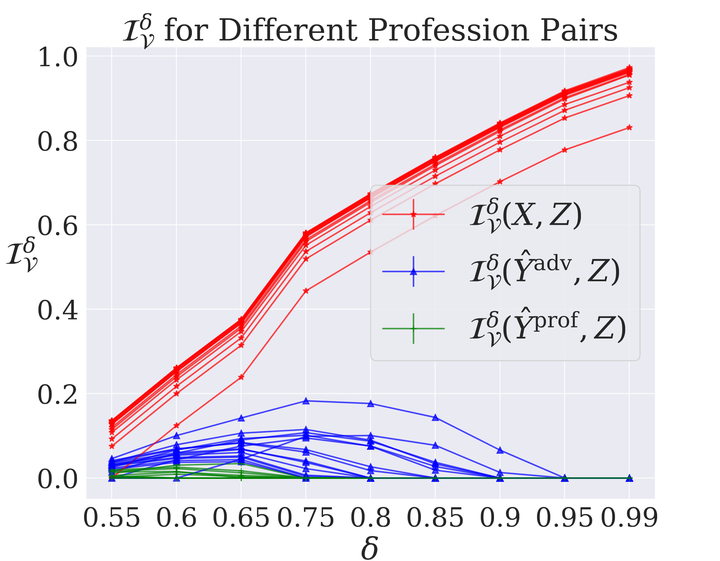
Linear methods for erasing human-interpretable concepts from neural representations were found tractable and useful. However, the impact of this removal on the behavior of classifiers trained on the modified representations is not fully understood. In this work, we formally define the notion of linear guardedness as the inability of an adversary to predict the concept directly from the representation and study its implications. We show that, in the binary case, an additional linear layer cannot recover the erased concept. However, we demonstrate that multiclass softmax classifiers can be constructed that indirectly recover the concept, pointing to the inherent limitations of linear guardedness as a bias mitigation technique. These findings shed light on the theoretical limitations of linear information removal methods and highlight the need for further research on the connections between intrinsic and extrinsic bias in neural models.