Abstract
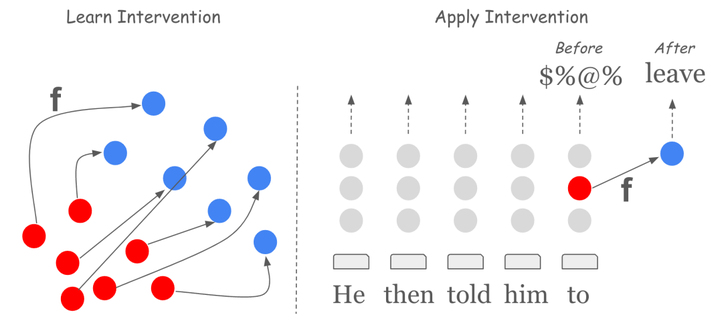
Language models often exhibit undesirable behavior, e.g., generating toxic or gender-biased text. In the case of neural language models, an encoding of the undesirable behavior is often present in the model’s representations. Thus, one natural (and common) approach to prevent the model from exhibiting undesirable behavior is to steer the model’s representations in a manner that reduces the probability of it generating undesirable text. This paper investigates the formal and empirical properties of steering functions, i.e., transformation of the neural language model’s representations that alter its behavior. First, we derive two optimal, in the least-squares sense, affine steering functions under different constraints. Our theory provides justification for existing approaches and offers a novel, improved steering approach. Second, we offer a series of experiments that demonstrate the empirical effectiveness of the methods in mitigating bias and reducing toxic generation.